
|
|
|
 View source on GitHub View source on GitHub
|
Overview
This tutorial demonstrates how to visualize and perform clustering with the embeddings from the Gemini API. You will visualize a subset of the 20 Newsgroup dataset using t-SNE and cluster that subset using the KMeans algorithm.
For more information on getting started with embeddings generated from the Gemini API, check out the Python quickstart.
Prerequisites
You can run this quickstart in Google Colab.
To complete this quickstart on your own development environment, ensure that your envirmonement meets the following requirements:
- Python 3.9+
- An installation of
jupyterto run the notebook.
Setup
First, download and install the Gemini API Python library.
pip install -U -q google.generativeai
import re
import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import google.generativeai as genai
import google.ai.generativelanguage as glm
# Used to securely store your API key
from google.colab import userdata
from sklearn.datasets import fetch_20newsgroups
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
Grab an API Key
Before you can use the Gemini API, you must first obtain an API key. If you don't already have one, create a key with one click in Google AI Studio.
In Colab, add the key to the secrets manager under the "🔑" in the left panel. Give it the name API_KEY.
Once you have the API key, pass it to the SDK. You can do this in two ways:
- Put the key in the
GOOGLE_API_KEYenvironment variable (the SDK will automatically pick it up from there). - Pass the key to
genai.configure(api_key=...)
# Or use `os.getenv('API_KEY')` to fetch an environment variable.
API_KEY=userdata.get('API_KEY')
genai.configure(api_key=API_KEY)
for m in genai.list_models():
if 'embedContent' in m.supported_generation_methods:
print(m.name)
models/embedding-001 models/embedding-001
Dataset
The 20 Newsgroups Text Dataset contains 18,000 newsgroups posts on 20 topics divided into training and test sets. The split between the training and test datasets are based on messages posted before and after a specific date. For this tutorial, you will be using the training subset.
newsgroups_train = fetch_20newsgroups(subset='train')
# View list of class names for dataset
newsgroups_train.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']
Here is the first example in the training set.
idx = newsgroups_train.data[0].index('Lines')
print(newsgroups_train.data[0][idx:])
Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is all I know. If anyone can tellme a model name, engine specs, years of production, where this car is made, history, or whatever info you have on this funky looking car, please e-mail. Thanks, - IL ---- brought to you by your neighborhood Lerxst ----
# Apply functions to remove names, emails, and extraneous words from data points in newsgroups.data
newsgroups_train.data = [re.sub(r'[\w\.-]+@[\w\.-]+', '', d) for d in newsgroups_train.data] # Remove email
newsgroups_train.data = [re.sub(r"\([^()]*\)", "", d) for d in newsgroups_train.data] # Remove names
newsgroups_train.data = [d.replace("From: ", "") for d in newsgroups_train.data] # Remove "From: "
newsgroups_train.data = [d.replace("\nSubject: ", "") for d in newsgroups_train.data] # Remove "\nSubject: "
# Put training points into a dataframe
df_train = pd.DataFrame(newsgroups_train.data, columns=['Text'])
df_train['Label'] = newsgroups_train.target
# Match label to target name index
df_train['Class Name'] = df_train['Label'].map(newsgroups_train.target_names.__getitem__)
# Retain text samples that can be used in the gecko model.
df_train = df_train[df_train['Text'].str.len() < 10000]
df_train
Next, you will sample some of the data by taking 100 data points in the training dataset, and dropping a few of the categories to run through this tutorial. Choose the science categories to compare.
# Take a sample of each label category from df_train
SAMPLE_SIZE = 150
df_train = (df_train.groupby('Label', as_index = False)
.apply(lambda x: x.sample(SAMPLE_SIZE))
.reset_index(drop=True))
# Choose categories about science
df_train = df_train[df_train['Class Name'].str.contains('sci')]
# Reset the index
df_train = df_train.reset_index()
df_train
df_train['Class Name'].value_counts()
sci.crypt 150 sci.electronics 150 sci.med 150 sci.space 150 Name: Class Name, dtype: int64
Create the embeddings
In this section, you will see how to generate embeddings for the different texts in the dataframe using the embeddings from the Gemini API.
API changes to Embeddings with model embedding-001
For the new embeddings model, embedding-001, there is a new task type parameter and the optional title (only valid with task_type=RETRIEVAL_DOCUMENT).
These new parameters apply only to the newest embeddings models.The task types are:
| Task Type | Description |
|---|---|
| RETRIEVAL_QUERY | Specifies the given text is a query in a search/retrieval setting. |
| RETRIEVAL_DOCUMENT | Specifies the given text is a document in a search/retrieval setting. |
| SEMANTIC_SIMILARITY | Specifies the given text will be used for Semantic Textual Similarity (STS). |
| CLASSIFICATION | Specifies that the embeddings will be used for classification. |
| CLUSTERING | Specifies that the embeddings will be used for clustering. |
from tqdm.auto import tqdm
tqdm.pandas()
from google.api_core import retry
def make_embed_text_fn(model):
@retry.Retry(timeout=300.0)
def embed_fn(text: str) -> list[float]:
# Set the task_type to CLUSTERING.
embedding = genai.embed_content(model=model,
content=text,
task_type="clustering")
return embedding["embedding"]
return embed_fn
def create_embeddings(df):
model = 'models/embedding-001'
df['Embeddings'] = df['Text'].progress_apply(make_embed_text_fn(model))
return df
df_train = create_embeddings(df_train)
0%| | 0/600 [00:00<?, ?it/s]
Dimensionality reduction
The length of the document embedding vector is 768. In order to visualize how the embedded documents are grouped together, you will need to apply dimensionality reduction as you can only visualize the embeddings in 2D or 3D space. Contextually similar documents should be closer together in space as opposed to documents that are not as similar.
len(df_train['Embeddings'][0])
768
# Convert df_train['Embeddings'] Pandas series to a np.array of float32
X = np.array(df_train['Embeddings'].to_list(), dtype=np.float32)
X.shape
(600, 768)
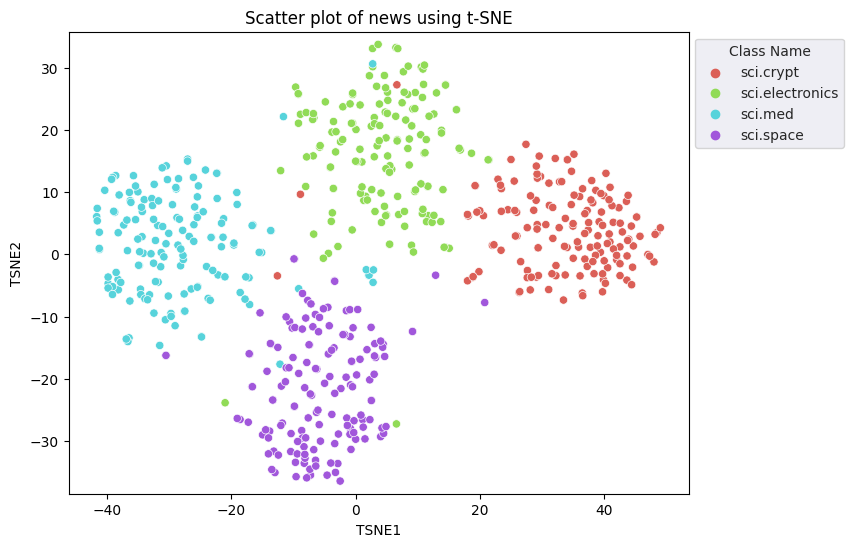
You will apply the t-Distributed Stochastic Neighbor Embedding (t-SNE) approach to perform dimensionality reduction. This technique reduces the number of dimensions, while preserving clusters (points that are close together stay close together). For the original data, the model tries to construct a distribution over which other data points are "neighbors" (e.g., they share a similar meaning). It then optimizes an objective function to keep a similar distribution in the visualization.
tsne = TSNE(random_state=0, n_iter=1000)
tsne_results = tsne.fit_transform(X)
df_tsne = pd.DataFrame(tsne_results, columns=['TSNE1', 'TSNE2'])
df_tsne['Class Name'] = df_train['Class Name'] # Add labels column from df_train to df_tsne
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Class Name', palette='hls')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using t-SNE');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
Compare results to KMeans
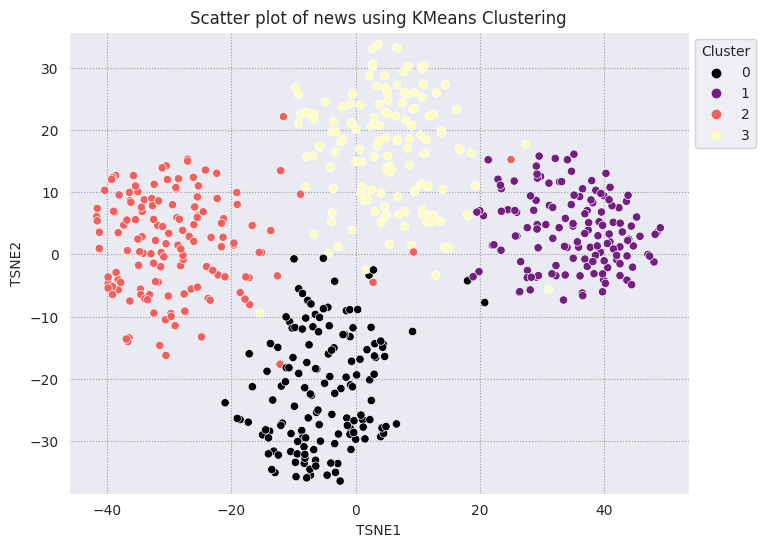
KMeans clustering is a popular clustering algorithm and used often for unsupervised learning. It iteratively determines the best k center points, and assigns each example to the closest centroid. Input the embeddings directly into the KMeans algorithm to compare the visualization of the embeddings to the performance of a machine learning algorithm.
# Apply KMeans
kmeans_model = KMeans(n_clusters=4, random_state=1, n_init='auto').fit(X)
labels = kmeans_model.fit_predict(X)
df_tsne['Cluster'] = labels
df_tsne
fig, ax = plt.subplots(figsize=(8,6)) # Set figsize
sns.set_style('darkgrid', {"grid.color": ".6", "grid.linestyle": ":"})
sns.scatterplot(data=df_tsne, x='TSNE1', y='TSNE2', hue='Cluster', palette='magma')
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.title('Scatter plot of news using KMeans Clustering');
plt.xlabel('TSNE1');
plt.ylabel('TSNE2');
plt.axis('equal')
(-46.191162300109866, 53.521015357971194, -39.96646995544434, 37.282975387573245)
def get_majority_cluster_per_group(df_tsne_cluster, class_names):
class_clusters = dict()
for c in class_names:
# Get rows of dataframe that are equal to c
rows = df_tsne_cluster.loc[df_tsne_cluster['Class Name'] == c]
# Get majority value in Cluster column of the rows selected
cluster = rows.Cluster.mode().values[0]
# Populate mapping dictionary
class_clusters[c] = cluster
return class_clusters
classes = df_tsne['Class Name'].unique()
class_clusters = get_majority_cluster_per_group(df_tsne, classes)
class_clusters
{'sci.crypt': 1, 'sci.electronics': 3, 'sci.med': 2, 'sci.space': 0}
Get the majority of clusters per group, and see how many of the actual members of that group are in that cluster.
# Convert the Cluster column to use the class name
class_by_id = {v: k for k, v in class_clusters.items()}
df_tsne['Predicted'] = df_tsne['Cluster'].map(class_by_id.__getitem__)
# Filter to the correctly matched rows
correct = df_tsne[df_tsne['Class Name'] == df_tsne['Predicted']]
# Summarise, as a percentage
acc = correct['Class Name'].value_counts() / SAMPLE_SIZE
acc
sci.space 0.966667 sci.med 0.960000 sci.electronics 0.953333 sci.crypt 0.926667 Name: Class Name, dtype: float64
# Get predicted values by name
df_tsne['Predicted'] = ''
for idx, rows in df_tsne.iterrows():
cluster = rows['Cluster']
# Get key from mapping based on cluster value
key = list(class_clusters.keys())[list(class_clusters.values()).index(cluster)]
df_tsne.at[idx, 'Predicted'] = key
df_tsne
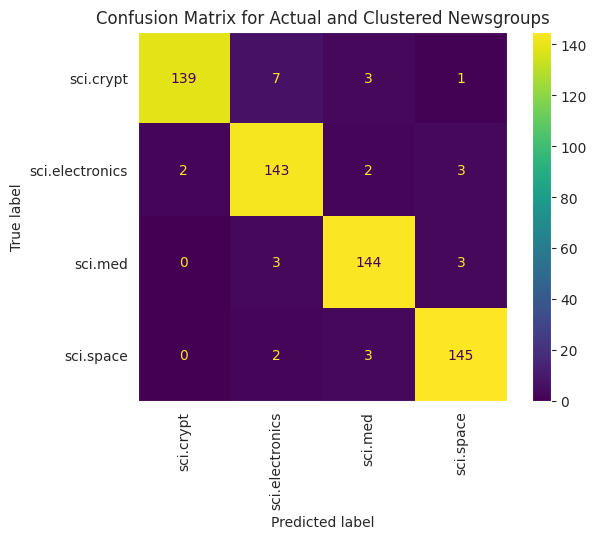
To better visualize the performance of the KMeans applied to your data, you can use a confusion matrix. The confusion matrix allows you to assess the performance of the classification model beyond accuracy. You can see what misclassified points get classified as. You will need the actual values and the predicted values, which you have gathered in the dataframe above.
cm = confusion_matrix(df_tsne['Class Name'].to_list(), df_tsne['Predicted'].to_list())
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels=classes)
disp.plot(xticks_rotation='vertical')
plt.title('Confusion Matrix for Actual and Clustered Newsgroups');
plt.grid(False)
Next steps
You've now created your own visualization of embeddings with clustering! Try using your own textual data to visualize them as embeddings. You can perform dimensionality reduction in order to complete the visualization step. Note that TSNE is good at clustering inputs, but can take a longer time to converge or might get stuck at local minima. If you run into this issue, another technique you could consider are principal components analysis (PCA).
There are other clustering algorithms outside of KMeans as well, such as density-based spatial clustering (DBSCAN).
To learn how to use other services in the Gemini API, visit the Python quickstart. To learn more about how you can use the embeddings, check out the examples available. To learn how to create them from scratch, see TensorFlow's Word Embeddings tutorial.